



The Good, the Bad, and the Ugly Science of AI in Education
What would you learn if you scoured the peer reviewed studies out there on AI in education? I did, and I wasn't ready for it.


Preface: Down the Rabbit Hole
The work I performed for this article changed me. I am confident that the document I’m about to share with you is unique in both its scope and accuracy. I didn’t set out to do what I ended up accomplishing at first. It’s what I found that compelled me to turn what I thought would be a rather brief article, quick and fun to write, into several dozen hours collecting information on the existing science of AI in Education and getting psychologically scarred in the process. Spoiler alert, I’ll be exposing incompetence, lack of integrity, and downright confirmed fraud in this article. That’s why I kept at it for so long, I don’t expect my reader to take my word at face value, I want you to be like me. I am rather skeptical by nature, some would say contrarian, that's fine.
I might sound frustrated in this article, even angry at times. That’s because I am, and you will be too, once you’re through with it (almost 6,000 words). Upon starting I didn't realize my search would take me down a smelly rabbit hole in which, the more I dug, the more it stank. I would then dig some more, pining for some fresh air, and I did find some, sparsely, but I also inevitably found more stench. I had no idea science could be so bad. And before you leave, thinking this is some kind of clickbait manoeuvre, let me tell you right now that not only have I been as exhaustive as I could, but I documented everything in case you don't believe me. I did not keep track of exactly how many hours I spent poring over "scientific" papers, opening 8 new tabs from a source then branching in several tabs each from the reference lists, and trying to zero in on the studies that pretended to study learning gains attributed to student use of genAI. It's 2025, right? ChatGPT's been here for 27 months and the whole world is yapping about it. Surely some competent people out there tried to answer the bloody question everybody's wondering about: is it going to help with education?
No one who's either talked to me or read one of my articles would call me a luddite, but what may come as a surprise is that I find myself being equally annoyed by AI skeptics who get a kick out of reading about failed AI enterprises and seem to always come off as "see, there's nothing AI can do about that!", as by AI enthusiasts who are touting it day in, day out, as the education panacea. We all know the influence of genAI on education is... complex. Which is why, a little bit over 2 years after the release of ChatGPT and the worldwide freakout about AI, I thought it'd be a good idea to take you on a tour of what Science has to say. But first let me tell you about something that will foreshadow my thesis and expose an idiosyncrasy of our society, a bad habit that you too may very well be guilty of…

Sharing Without Clicking
A very recent study by Penn State University researchers published in Nature analyzed over 35 million public Facebook posts containing links shared between 2017 and 2020. An anterior study from 2016 had done the same for Twitter. The kick is that when you have access to social media data like this, you can look for interesting facts, such as whether or not the person sharing an article actually clicked on the link to open said article (and read it)... How bad do you think it was?
The results weren't pretty: around 75% of the shares on Facebook were made without the posters ever clicking the link to read the actual article. On Twitter it was barely better: a whopping 59%. This implies that a majority of people retweeting news stories and hot takes haven't actually read past the headline, making Facebook and Twitter even worse breeding grounds for misunderstandings and misinterpretations than I even thought! It seems "sharing without clicking" or "SwoCs" as the researchers labeled it (does it count for Scrabble?) is a ubiquitously widespread phenomenon across social media platforms.
"Findings suggest that the virality of political content on social media (including misinformation) is driven by superficial processing of headlines and blurbs rather than systematic processing of core content, which has design implications for promoting deliberate discourse in the online public sphere."
I knew this, which is how I found these studies, and when I'm pressed by time and can't read a full article, I always try to wait before sharing. Could I have failed on occasion? Most certainly, but I still try hard to suppress the urge to click that share button because I find it very irritating when someone does it to me and I catch them because I read the darn article - and find out they have not. So I try to not do that to people, and most definitely never in a professional context.
What’s particularly problematic with this is that journalists and editors are also aware of this fact and often use and abuse it to twist facts and lie by omission. When called out they can always hide behind the fact that the truth was there in the article for everyone to see, yet the harm is done, the fire of misinformation is fueled, and studies show that once people get set on an idea, it's incredibly difficult to make that false idea disappear. This phenomenon is called belief perseverance, and that’s one way media outlets are used to craft false and stubborn narratives by distorting the truth without actually lying (Lewandowsky et al., 2017 ; Entman, 1993). Don’t shoot the messenger, all sides are guilty.
What does this have anything to do with AI in education?? I hear you thinking…
I'm getting to it, don't worry.
While this SwoC-ing and despicable trend of mincing words in headlines may be known, documented, or even just suspected by many, you may find it surprising that a similar phenomenon is at play with scientific literature, and that only reading a study's title and abstract can also often be misleading. Sometimes, the true understanding of the findings can only be achieved after careful review of the protocols, starting hypotheses, sometimes all the way down to the appendices. This is particularly sneaky, because while SwoC-ing a press article can legitimately be qualified as lazy, not reading every single study down to the appendices is eminently understandable. I had assumed that the title and abstract of published scientific studies were faithfully describing the findings, and that the rest of the papers served as demonstration. In other terms, I thought I could trust scientists, or if not them, their advisors, or publishers, or the peers who review the articles. Boy, was I naive...
Of course, now that I'm making such a claim, I can't limit this article to a few examples to back my contention, and deliver a standard one-odd-thousand-word article. If you've read any of my past work, you know I take great pains to show the full picture - because so few do! That's why I started writing in the first place. I'm writing articles I wish I could read. And what I really want is to be thorough because, as Nassim Taleb would say: "absence of evidence isn't evidence of absence", just go ask the first European dudes who saw a black swan when they got to Australia.

What I did is scour the academic landscape for studies specifically claiming to measure the impact of AI on learning outcomes. I focused on research published from 2023 onward, since ChatGPT's November 30, 2022 release marked a clear dividing line. While AI has been present in education for years, ChatGPT and other large language models represent a fundamental shift - they've completely reshuffled the deck, bringing tools that are qualitatively different and have penetrated the educational market with unprecedented speed and reach. It's truly been everything, everywhere, all at once.

Methodology
Influenced by the critical eye of Dan Meyer in this respect, I became demanding about experimental protocols, control groups, segment size, age and disposition, and especially, as we'll see, about what I call Assessment Post-Treatment. At this point I need to define a few terms, some standard and some my own, in case you're a little rusty with scientific study jargon, because without this, you might miss some important nuances in my appalling findings...
Scientific study: Ideally, a paper written by well-read people who honestly tried to answer a complicated question by accumulating and analyzing evidence, and then faithfully reporting on what happened.
Segment or sample: the guinea pigs; the people being observed by the white coats.
Experimental Group (EG): the part of the sample that is given the "treatment" or "intervention", in this case AI in some capacity to help in their learning. In this column of my table, I exhaustively added all the details that were given about the administered treatments. You’ll see that for most of them, it wasn’t much.
Control group, or CG: the rest of the sample who do not get the treatment, in this case no AI. The control group is supposed to allow researchers to isolate the treatment variable so that the results observed in the EG can actually be attributed to the treatment. It seems like common sense, right? Well, prepare to be disappointed.
Status: PP for “pre-print”, UR for “under review”, PR for “peer-reviewed”.
Age: UE for “upper elementary”, MS/HS for “middle/high school”, UN for “undergrad”, GD for “graduate”, and AD for “adult”.
What I’ve dubbed Assessment Post-Treatment, or APT, or post-intervention test, or post-test, or anything that sounds like this: This is a test you're giving the experimental group AFTER the treatment, or intervention, to see if there are any learning gains that can be attributed to said intervention. Common sense, you know? Like “hey, let's give ChatGPT, or something, to these kids so they can learn for a while, then we try to figure out if they have learned anything?” Seems obvious? There too, don't get your hopes up. Here's the scale I used in my table where you'll find all the results and my observations. Click this.

I included all the elements that could allow my readers to check if I’m accurate. If I made any mistakes, please let me know and I will correct them. Pay attention to the titles and the findings of each study. In the findings, I directly quoted or paraphrased from the papers. There’s a color code in the findings: green for positive, grey for neutral, red for negative. Note that once we get out of green check mark territory, and except for 2 neutral papers, all of the studies claim a positive impact on learning outcomes.
I created a custom GPT to help me analyze the papers critically, I called it Professor Real, and I made it public so you too can use it if you want. I did NOT rely exclusively on AI for this work, I could not. I had to know for myself I was telling the truth. In the Wess’s Two Cents column you’ll find my honest and informed assessment of all the studies. I must have reviewed close to a hundred papers, but only included in my table the ones who purportedly investigated learning outcomes due to AI use. What you’ll find is 40 studies, 32 of which are peer reviewed. I felt compelled to display all the relevant studies I've come across so I can feel secure that my reader will have a decent amount of trust that I exhausted all possibilities of being wrong before I claimed some of your time. Not like this guy who wrote one of the most idiotic posts I've ever seen. I'm calling him by name to single him out, sure, but if you read his article - I stumbled upon it during my research, you would agree with me. In this article he claims that one of the ways AI is currently "revolutionizing" education is humanoid robots in the classrooms! And that's just the most obvious proof the guy hasn't set foot in a school in a very long time, the rest is just the kind of great sounding slogans that understandably make skeptics mad. Just go check it out, I'll wait here.
The integrality of my findings is compiled in the table I just shared with you, I’m not going to go over the entire thing in the article. Here I’ll just highlight a few studies illustrating what I mean by the good, the bad, and the ugly science.

The Good Science
Let's start with the good science. To be clear, my standards weren't impossibly high. To make it into this category, studies simply needed a basic experimental setup that:
Used a control group to properly isolate the AI treatment's effects
Included an assessment post-treatment to quantitatively measure actual learning gains
That's it.
I want to make it clear that even in this group, I sometimes have suspicions of shenanigans, but on paper everything seems legit. If there are lies in there, they're good convincing lies. Since there is no ground for me to call them out, I have to be fair and give them a green check mark. That's 15 studies out of 40, yet even among these better studies, there are limitations. Most lack detailed information about the exact AI model used, the specific training provided to students, or clear guidelines given during the experiment. This makes replication nearly impossible without extensive consultation with the original authors – a fundamental issue in scientific research.
Nevertheless, here are some of the most noteworthy findings from what appear to be trustworthy papers:
Generative AI Can Harm Learning, Bastani et al. 2024, from Wharton
Let's get this one out of the way since it's the most painful one to read about for people who are hoping AI can usher in educational prosperity for all. While the paper doesn't yet have the peer-review sticker on it, it is by far one of the most solid studies I've come across. Very large sample of about a thousand high school students divided in two experimental groups (EG) and one control group (CG). One EG had a custom GPT tutor (system prompt included on page 22), another just had access to basic ChatGPT, and the control group received the same instruction, but no AI at all. All the students were subsequently assessed without the help of AI, and while performance during practice was dramatically higher in both EGs, both groups underperformed the CG at the post-treatment assessment. The base-ChatGPT group underperformed significantly, and the GPT custom tutor group not significantly, but still. This is solid evidence that over-reliance on LLMs is a very real challenge that will need to be addressed as access to LLMs is almost impossible to restrict.
AI Tutoring Outperforms Active Learning, Kestin et al., 2024, from Harvard
Another very solidly designed study with a consequential segment of 200 students, the EG had access to a custom bot based off of API GPT-4-0613 (system prompt page 11), while the CG received active learning instruction. It found that students learned "more than twice as much in less time when using the AI tutor" which is VERY encouraging... Until you realize that the sample was entirely composed of undergrad physics nerds from Harvard. Hardly a generalizable sample, I think we'll all agree on that.
Exploring the Effectiveness of AI Course Assistants on the Student Learning Experience, Hanshaw et al., 2024, from Los Angeles Pacific University
This one just made the cut since I learned about it yesterday morning by reading fellow substacker Nick Potkalitsky, whose channel I recommend. This is one of the few promising studies that suggest that careful instructional design in which AI's role is thoughtfully calibrated can indeed bring learning gains. In this case we're talking about 92 undergrad students. The EG is provided with asynchronous online courses, teacher support, and "access to AI course assistants developed by Nectir.io" while the CG had the same instruction and support, minus the AI. My digging revealed that Nectir.io is a sandboxed custom bot built off of GPT-4o, and meant to be FERPA compliant. Sandboxed means that while they're using an API, they're not sharing any data with openAI. Their whole spiel is data privacy. Anyways, the researchers found that the EG performed 10% higher than the CG. More details in the table.
These were 3 of the best studies I found, the first two I already knew about BEFORE I spent the aforementioned dozens of hours reading lame science. What's striking about even the good studies is how modest the findings tend to be. The dramatic claims about AI revolutionizing education simply aren't supported by rigorous evidence. When proper controls and measurements are in place, we see some benefits in specific contexts, but nothing resembling the transformative revolution so often proclaimed. Go check the table, read about the 12 other good science studies, then take one last deep breath, we're crossing into smelly territory.

The Bad Science
Moving into the realm of bad science, this is where the majority of studies I examined fall. What makes them "bad" isn't necessarily that they're entirely worthless, but that their methodology contains fatal flaws that render their conclusions questionable at best and misleading at worst. This category represents 18 out of 40 studies, or almost half of them.
The most common issues I encountered were:
No control group – Without this, how can you attribute any changes to the AI intervention rather than other factors?
No assessment post-treatment – If you don't measure what students learned after using AI, how can you claim it improved learning?
Reliance on self-reported perceptions – Students saying they "feel" they learned more isn't the same as demonstrating actual learning gains.
Then, there's what I call the "dead horse" category – studies that go to extraordinary lengths to prove what is already painfully obvious. I found myself repeatedly bewildered that researchers would invest significant time and resources to demonstrate that, for example, "using ChatGPT improves your performance on a test." Of course it does! That's like conducting a study to prove that "calculator use improves speed in solving complex arithmetic problems." I'm not kidding, I'll give you examples, but before we do, let's do a test together:
এই প্রশ্নটি অনুবাদ করতে তুমি কত সময় নষ্ট করলে ?
Answer the question without the use of AI (the answer is not subjective).
Use any AI you want, ChatGPT or even Google Translate, and try again.
Subtract your non-AI score from your AI-augmented one, and then divide the difference by your non-AI score
Unless you are fluent in Bengali, you just proved AI can provide infinite learning gains. Congratulations, where's my Nobel prize?
Seriously, I couldn't believe people would go through the pain of producing a scientific paper to show something so glaringly obvious as "Students with higher AI literacy, prior Python knowledge, and a better understanding of ChatGPT perform better at solving programming problems with ChatGPT." (Jing et al., 2024) Did the world really need research to confirm this? Anyway, here are a few select examples of the bad peer reviewed science I found.
How to harness the potential of ChatGPT in education? Zhu et al., 2023, from Hong Kong University
Findings: "we propose how ChatGPT can be properly integrated into teaching and learning practice to harness its potential in education."
22 pages of hot air: purely theoretical, 100% opinion based paper, no experiment whatsoever. What's the point?
Improving Student Learning with Hybrid Human-AI Tutoring: A Three-Study Quasi-Experimental Investigation, Thomas et al. 2024, from Carnegie Mellon University
This is one example of a recent 2024 study on AI in education that never even mentions ChatGPT or large language models. The sample is composed of 600 middle school students where different EGs are provided with access to different Adaptive Learning Platform (ALP) such as IXL or iReady and a human tutor, while the control groups only have the ALPs. Their findings?
"The study found that human-AI tutoring, where AI tools assist human tutors, has positive effects on student learning, particularly in increasing student proficiency and software usage, with lower-achieving students potentially benefiting more."
I have several problems with this study. You may have caught the first one from what I just divulged: The EG had AI + human tutor, and the CG the same AI, no human tutor. This means the variable is the human tutor, AI has nothing to do with the findings. Second, if IXL-type technology brought great learning gains, I think we would know by now. Laurence Holt, in his great article The 5 Percent Problem explained what the issue was with the research showing significant learning gains from ALP-type AI products. I'll save you some time and bold a few critical passages.
"Do they work? In August 2022, three researchers at Khan Academy, a popular math practice website, published the results of a massive, 99-district study of students. It showed an effect size of 0.26 standard deviations (SD)—equivalent to several months of additional schooling—for students who used the program as recommended.
A 2016 Harvard study of DreamBox, a competing mathematics platform, though without the benefit of Sal Khan's satin voiceover, found an effect size of 0.20 SD for students who used the program as recommended. A 2019 study of i-Ready, a similar program, reported an effect size in math of 0.22 SD—again for students who used the program as recommended. And in 2023 IXL, yet another online mathematics program, reported an effect size of 0.14 SD for students who used the program as designed."
See the catch? Just how many kids do use the programs "as recommended"? Holt reports that in-depth investigation reveals we're barely dealing with 5% of the kids, and the 5% from higher income households at that, and higher achievers, i.e. the kids who don't really need it. Other kids see "minimal gains, if any."
The third problem is much harder to spot because it's what's unsaid amidst the 12 pages of text in font size 6. They say the kids took a Star Diagnostic standardized adaptive norm-referenced assessment 9 times throughout the 40 weeks of the experiment, and only reported on student engagement, lesson completion rates, and time spent on AI-assisted tutoring - not on performance! Why the F*CK not??! Not only that, they do mention the poor performance of the school the previous year on the state test, but fail to mention the state test results the year of the intervention when they were tracking data all year!
Now tell me, am I being unreasonable here? Do you think it did not occur to them they could include longitudinal performance across 9 standardized assessments throughout the intervention, or performance on the high stake state test to compare to the previous year? Or do you think they decided not to include it, because... I'll let you finish. I can't prove anything, but I don't like the smell of that. This study has been cited 16 times according to ResearchGate, and none of the citations I looked at called this out, many used it to back their claims of proven learning gains.
As you go through the studies with a red X mark in the table, pay close attention to the wording of the findings. A lot of people are going to great lengths to have something positive to say, I wonder why that is. Anyway, let's have some fun now, before we hit rock bottom.

The Dead Horse Studies
That's what my pal Professor Real and I started calling studies that were really beating dead horses. No less than 8 studies reviewed earned that sticker, that's 20% of my sample. I don't think I need to go into details here, I'm not even going to cite or link the studies, go check out the table if you're curious. I'll just do a rapid fire so we can all have a good laugh.
A study found that AI assistance had positive effects on writing motivation, self-efficacy, engagement, and collaborative writing tendency. No Assessment Post-Treatment (APT) to quantify anything.
Another one found that constructivist, game-based, and project-based learning approaches are the most effective. They did not do any experiment or measure anything, did not look at performance, only engagement.
Another one "discovered" that students with better AI skills and programming knowledge perform better at using an AI tool for programming, who could have guessed? Worse, without a control group, it fails to show whether ChatGPT actually improves learning beyond what students could achieve with traditional methods. Cherry on the cake: the post-test included the use of AI...
Another one found that students significantly improved their critical evaluation skills when tasked with assessing AI-generated content. Without a control group, this study doesn't actually prove that ChatGPT itself improved critical thinking—it only proves that critiquing essays is an effective learning method. We all know that.
Am I exaggerating? Am I being unfair? What troubles me most for these red X mark and dead horse studies is the complete failure of accountability at every level – the researchers who designed these studies, their advisors who approved them, the universities that sanctioned them, the journals that published them, and the peer reviewers who didn't call out these obvious shortcomings. WTF is everybody doing? Is everybody pretending to do science all day long? What's the deal? I do not understand. Let's move on...
The Ugly Science
Now we arrive at the truly disturbing category: what I can only characterize as academic malpractice. These aren't merely flawed studies – they represent flagrant violations of scientific integrity that somehow slipped through the supposedly rigorous peer review process and all that double-blind bullshit.
What I uncovered here is genuinely concerning:
Fake citations – references to papers that don't exist or don't say what they're claimed to say
Fake references – including completely fabricated sources
AI-generated content – passages clearly written by language models, not humans, without disclosure
Clearly overblown conclusions, not supported by data
I thought the entire point of peer review was to eliminate all cracks through which such shoddy work could slip? Apparently not.
The most egregious examples include:
Exploring the Impact of Artificial Intelligence in Teaching and Learning of Science: A Systematic Review of Empirical Research, Almasri 2024, from Toronto Metropolitan University
Start reading this "systematic review" and you'll quickly realize that under the "AI" label, this study is lumping together a bunch of different products. It was published in 2024 yet half of the 74 studies retained by the author date from 2021 or earlier i.e. well before the release of chatGPT, yet this fact is never clearly acknowledged. There are 10 studies dating from 2022, and even if I highly doubted any studies on chatGPT could have been whipped up under 31 days after its release (11/30/2022), I nonetheless decided to take a look to be sure...
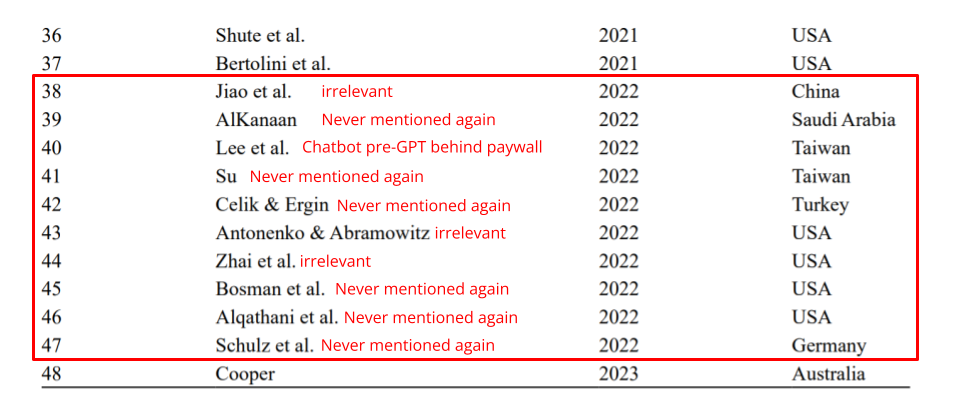
That's right, out of 10 studies from 2022 listed in their final list, 1 is about a chatbot but pre-GPT since it was published in August 2022 (I couldn’t see it, I wasn’t going to pay for that), 3 are completely irrelevant (using AI to predict or assess stuff), and 6 are never mentioned again in the document. The names of the authors listed are never actually referenced, and only appear in the list of 74 selected studies for the review.
When I saw this I went to look for their screening process. It's detailed page 7, here's what it says (accents mine):
“We started by searching through loads of databases and found 5,121 articles. After getting rid of duplicates, checking publication dates and titles, and looking at abstracts to see if they met the eligibility criteria for the present study, we ended up with 128 articles. From there, we excluded 41 studies because they didn't really dive into science education. That left us with 87 articles that we pored over super carefully. We made sure they fit our criteria and answered our research questions before diving into them. From the pool of these 61 articles, ten (13) studies were identified as lacking clear empirical evidence regarding the use of artificial intelligence and were subsequently excluded. This process resulted in a final dataset of 74 articles that were included in the systematic review.”
What do you think? I did not get stuck on the bizarre math in this passage, and I did not give up just yet, I really looked for claims of learning gains due to LLMs, and I finally found it at the end of page 9, continued at the beginning of page 11. The ONLY direct claim of learning games linked to usage of ChatGPT:
“AI-based tools were found to have a positive influence on student' learning outcomes in science-related courses. The experimental group that was exposed to AI integration in their learning environments exhibited significantly higher scores in their academic tests compared to the control group who experienced traditional learning environments (Alneyadi & Wardat, 2023).”
And this, ladies and gentlemen, is how I found the worst of the worst.

ChatGPT: Revolutionizing student achievement in the electronic magnetism unit for eleventh-grade students in Emirates schools, Alneyadi & Wardat, 2023, from Al Ain University, UAE
I thought I had it, finally, THE study that contradicted the Wharton one, the first one I told you about, I was very eager to read it, but as soon as I started I saw something I knew very well. Here's part of the introduction, accents are mine:
“In recent years, AI has garnered significant attention in the realm of education, particularly within intelligent tutoring systems (ITS). Among the most promising AI models in this field is the generative pretrained transformer (GPT), renowned for its capability to generate human-like text responses across a wide range of inputs. The integration of GPT in education holds the potential to revolutionize traditional teaching approaches by providing personalized and interactive learning experiences for students. This study aims to explore the impact of ChatGPT on student achievement in the electronic magnetics unit among tenth graders in the UAE (Al-Shehri et al., 2021).
Research has demonstrated that incorporating GPT into education can enhance student achievement through the provision of personalized feedback and interactive learning experiences. When applied to STEM subjects like electronic magnetics, GPT can assist students in comprehending intricate concepts and theories by offering real-time explanations and illustrative examples. Nonetheless, there is a scarcity of research regarding the effects of ChatGPT on the academic performance of tenth-grade students studying electronic magnetics in the UAE (Wardat et al., 2023).”
I know chatGPT-writing when I see it, did you see it as well? Nevermind the fact that ITS and GPT have absolutely nothing in common, the bolded sentences, asserted without references are the just classic tropes we read about in stupid articles like the idiot’s one I showed you earlier. In this passage, the first reference is weird, because it's in a sentence where they say what the study is about, and it mentions chatGPT when the referenced study is from 2021. Weird. The second reference at the end is a self-reference, that's the author of the present paper. You can't back a claim with your own word (Trabelsi, 2025), even though what they say is probably true.
From there I went full forensic on this paper and looked for references alleging learning gains due to LLMs. On page 4 there is a claim that "AI and ML can customize instruction according to the specific needs and abilities of individual students, leading to enhanced learning outcomes (Baker, 2020)”, once again the classic trope of personalized instruction. This Baker, 2020 led me to the references to find "Baker, R. S. (2020). The impact of artificial intelligence on education. Journal of Educational Psychology, 112(4), 662-677." Which leads to nowhere.com. I confirmed with the journal that this citation is a fake.
On page 5, I found this claim:
"Another study titled ‘Investigating the effectiveness of Chatbot's in higher education: A case study’ by Zhu et al. (2023) was published in the Journal of Educational Technology & Society. The researchers evaluated the effectiveness of a chatbot, which employed NLP and ML algorithms similar to ChatGPT, in supporting students' learning in a Chinese language course. The study demonstrated that the chatbot was effective in providing personalized feedback and improving students' performance in the course."
The reference cited also leads to nowhere.com and I also received confirmation from the journal in question that this study does not exist. Then I gave up.
What's particularly troubling is how these papers are then cited by others, spreading misinformation throughout the academic ecosystem. Once published, these faulty studies become part of the foundation upon which future research is built – a classic case of building castles on sand. This study has been cited 76 times. One of my red X mark papers mentions it 24 times in 13 pages. This implies that none of the 76 people referencing this study saw any issue with it? Come ON!
What Have We Learned?
After this exhaustive review, what can we conclude about the impact of generative AI on education? Sadly, not much that's definitive.
The more rigorous studies tend to show that over-reliance on AI can be detrimental to learning – hardly a surprising finding. But they also suggest potential benefits when AI is used as a supplement rather than a replacement for traditional learning methods.
What's glaringly absent from all these studies is creative instructional design. Most researchers simply dropped AI into existing educational frameworks without reimagining how instruction might be fundamentally redesigned around these new tools. This suggests that the most interesting and valuable research on AI in education has yet to be done.
What we've definitely learned, however, is that scientific-looking papers cannot be trusted at face value. For some reason – perhaps publication pressure, funding incentives, or simple incompetence – a disturbing amount of research in this field is substandard. Some of what I found may be attributed to inexperience or oversight, but some clearly stems from dishonesty or a profound lack of academic integrity. I saw many meta-analyses and other scientific reviews, but I’ve never found any criticism or doubts, nothing even close to what I’m telling you right now.
Call me naive, but I found this reality profoundly depressing. It certainly won't soften my contrarian tendencies. If anything, it reinforces the need for skepticism and thoroughness when evaluating claims about educational technology.
As educators navigate the AI revolution, we deserve better guidance than what current research provides. We need studies that:
Properly isolate variables
Measure actual learning outcomes
Consider long-term impacts
Explore innovative instructional designs
Provide sufficient detail for replication
Until then, claims about AI's transformative potential in education should be met with healthy skepticism and a demand for evidence that actually deserves the label "scientific."
Thanks so much for sharing this analysis, Wess. Helping people who want to to be 'evidence-based' in their decisions better understand the evidence -- and the 'evidence' -- is often not a very glamorous task. When you do this, you don't get sexy publication credits or citations, but you do get admiration from many people who really care about separating fact from fiction -- and how to tell the difference. This is messy stuff, thanks for taking the time to sweep your broom in public like this!
This is very well done and accords with what I'm seeing too (see link below). Thanks for doing the hard work of looking into all this shoddy research.
https://buildcognitiveresonance.substack.com/p/something-rotten-in-ai-research