

My Long-Term Prediction for AI in Education
Do you want to know the future of AI EdTech? This article goes over what it technically is and where this is all going.


What's going to change over the next 5 years in the world of AI in EdTech?
“Not much.”
(Wess Trabelsi, May 2025)
This is basically the TL;DR for this article. I know… it's somewhat anticlimactic, which is why I'm not building any kind of suspense here. However, you might be interested to know how I arrived at this unorthodox conclusion, and why I think it's solid enough to take a public chance at forecasting long-term AI developments.
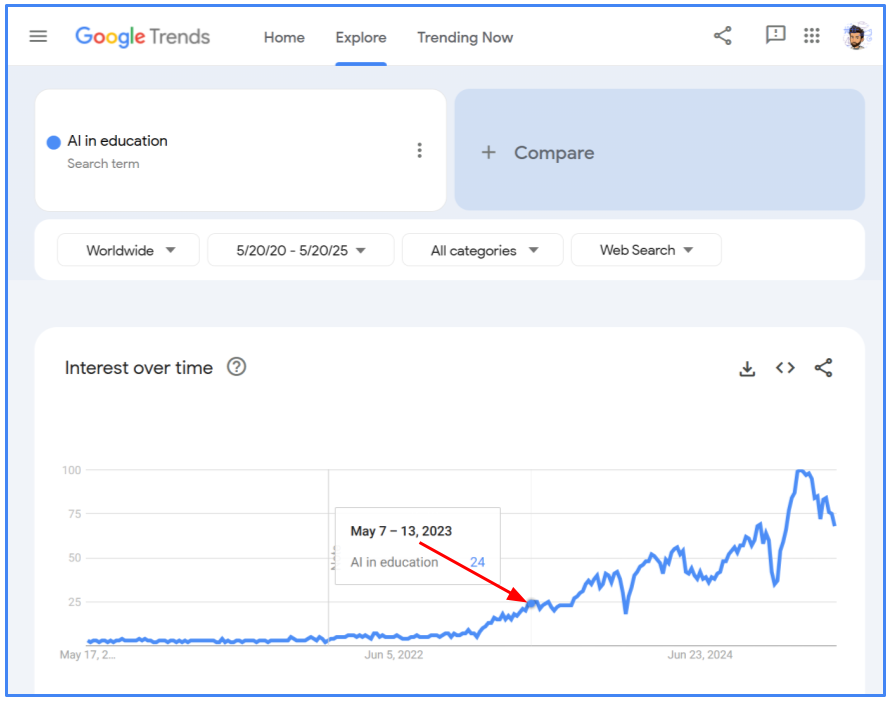
If you think 5 years isn't "long-term," I'll politely remind you that just 2 years ago, the AIED industry was a very different landscape. It consisted mainly of Intelligent Tutoring Systems that somewhat work if students really want to use them (e.g., they don't). Also, few people actually referred to these systems as "AI" outside of academia. Here's the Google Trends analysis for "AI in Education" over the past 5 years.
To demonstrate the solidity of my theory, I'll start by sharing the inner workings of AI tools for education, going even deeper than in my previous article on the topic. I had to build this understanding over time myself, not being particularly well-versed in computer science. But I read extensively on AI and haven't seen this explained in detail elsewhere, so that's what I'll do.
Once we're all on the same page about how these tools are built, it will be much easier to see 1. where this is all going and 2. the external factors that are making radical changes in this space impossible to quickly deliver at scale—even if the technology exists. The exponential frenzy of AI development is already hitting a very physical wall that no amount of money can make disappear.
It took me a while to piece this all together, but very recently, three key documents landed in my lap that provide all the backing I need. They should also give you a good sense of where I'm taking you:
the International Energy Agency's, or IEA, “Energy and AI” 2025 report,
the US Senate hearing titled "Winning the AI Race: Strengthening U.S. Capabilities in Computing and Innovation,"
and the Association for the Advancement of AI’s, or AAAI, "Future of AI Research" panel report.
Let's dig in...
The API Connection: How Educational AI Tools Really Work
When we talk about accessing the powerful foundation or frontier models from AI labs like OpenAI, Google, xAI, Anthropic, Meta, or Mistral (vive la France!), there are exactly two avenues for consumers and developers.
The most familiar route, of course, is through the public-facing chatbots that I just linked above. These user-friendly interfaces often offer free versions and paid subscriptions that unlock more advanced models. We all know the drill: to tailor a bot's behavior in a free version, your primary tool is prompt engineering. Paid subscriptions like ChatGPT Plus allow you to build Custom GPTs (or "Projects" in Claude, "Gems" in Gemini – all the same, really). These are specialized versions of chatbots pre-loaded with instructions and supporting documents—incredibly useful for recurring tasks where you'd rather not re-explain your context every time.
The second, and more pertinent route for our discussion is via the companies' API (Application Programming Interface) platforms. This is the gateway for anyone wanting to build a tool on top of these models, and it's precisely how all genAI tools for education are constructed. They're called "wrapper apps." Take a look at OpenAI's API pricing page. It's a pay-as-you-go system, with prices listed per million tokens (very roughly 1M words) for both input and output. The price differences are striking.

Notice the factor of a thousand between 4o-mini and o1 Pro. Which model do you think you're using with the free version of SchoolAI's copilot? That's right—if you input a million words in SchoolAI's copilot or student space and get a million words back (which would take some doing), you will have cost SchoolAI $0.75. This might sound trivial, but imagine a million people doing the same... Actually, they've thought of that, which is why every free access to an LLM comes with usage limits. Their generosity does have bounds, this is very understandable. The paying users are subsidizing the free tier - fair.
This is where things get a little more technical, but it’s crucial. Once a developer has chosen the model(s) for their tool and obtained an API key, there are exactly three ways they can "customize" the model to serve their specific needs. Let’s go over each, because this understanding is fundamental to grasping what’s truly possible with current AI tools.
Under the Hood: System Prompts, Fine-Tuning, and RAG
Let’s start with the easiest one: the System Prompt. If you’ve ever created a Custom GPT, this concept will be very familiar. If not, head to the footnotes1. The system prompt is where developers give the bot its core instructions—its personality, role, target audience, and overall purpose. For an AI tutor, this might look like: “You are a friendly, patient, and engaging tutor specializing in helping high school students prepare for Regents exams. Always begin by asking students what specific topic they want to work on. Strive to guide them to the answer through Socratic questioning rather than providing direct answers. If the student veers off-topic, gently redirect their attention back to the task at hand,” and so on. In essence, it's sophisticated prompt engineering embedded directly into the tool's foundation, yet it remains purely textual.
Then there's Fine-Tuning. This, too, is text-based (think raw .txt files). Fine-tuning involves training the base model on a curated dataset of specific prompt-and-completion pairs. The objective is to teach the model to respond in a particular, desired way to certain types of inputs, reducing the likelihood of it "guessing" or generating less relevant answers. This dataset might be a long list of entries such as: "If user says: 'you're a poopy head,' then respond: 'I enjoy your sense of humor, but we should focus on our mindfulness activity.'" To be effective for a wide range of anticipated interactions, these fine-tuning datasets need to be quite exhaustive, and I'd wager many are, somewhat ironically, at least partially AI-generated to achieve that scale. Here's what it actually looks like:
{"messages": [{"role": "user", "content": "your mama!"}, {"role": "assistant", "content": " is doing well, thank you. How's that polynomial factorization going for you?"}]}
Lastly, we have Retrieval-Augmented Generation (RAG). This is more complex but arguably the most impactful method for injecting specific, up-to-date, or proprietary knowledge into a model. Similar to how Custom GPTs allow you to upload reference documents, RAG is the primary mechanism that isn't just plain text instruction. This is how a developer could upload an entire curriculum, specific textbooks, or proprietary pedagogical data. The bot can then reference this information when generating responses. Once uploaded, these documents are "vectorized"—converted into a mathematical format that the language model can use. A key technical advantage of RAG, beyond providing domain-specific knowledge, is that it doesn't usually consume the model's "context window" (the amount of information the model can actively consider).
Now, here's the crucial takeaway about RAG, especially concerning its application in education: the bot can only retrieve and use the information from these documents. It operates at the lower rungs of Bloom's Taxonomy—remembering facts, comprehending texts. If you were building a "teacher bot" and uploaded the complete works of Lev Vygotsky, Jean Piaget, and Maria Montessori, your bot would become exceptionally skilled at citing these thinkers and answering direct questions about their theories. However—and this is a major distinction—it will not learn from these profound texts to become a better, more pedagogically adept teacher itself. It can accurately regurgitate pedagogical wisdom, but it doesn't internalize the principles to fundamentally improve its own "teaching" methodology.

To sum up: the system prompt is akin to detailed prompt engineering; fine-tuning helps to predetermine responses to specific, anticipated prompts; and RAG allows you to focus or expand the model's factual knowledge base. That, in essence, is the "customization" powering the vast majority of these AI educational wrapper apps. If you're comfortable with ChatGPT and understand these three components, you now possess a very clear insight into what "custom bots" can—and, more critically, cannot—currently achieve.
As time advances and computing power scales at the AI labs, the price per token of various tools like online search, image analysis, and extended reasoning will become economically viable to include in these educational wrapper apps. We'll likely see them first in premium, paid subscription tiers, eventually making their way into free offerings. Understanding this basic architecture means you'll always be one step ahead.
Here's another interesting insight from these observations: For all intents and purposes, textual interactions are virtually free and unlimited. I wonder how many tokens an involved student could consume, but at 15 cents per million tokens, it must take a while to become a financial burden. The price increases steeply when you use more advanced models requiring more computation, and when you introduce media that are more token-intensive, like images and video. This also explains why, while ChatGPT's advanced voice mode is great, the text-to-speech feature in most free educational AI tools sounds like it's 2015.
It all boils down to input and output: what kind of data and interaction do you truly need to create a genuinely effective educational product, such as a truly intelligent AI tutor, and what is the computational (and therefore financial) cost of delivering that?
Human tutor vs. AI tutor
My central thesis hinges on a simple observation: AI companies, for all their innovation, haven't yet imagined a pedagogical approach superior to a good human teacher. If anyone had a truly revolutionary, scalable alternative for educating children, we'd likely know by now. Instead, their efforts, constrained by what Large Language Models can fundamentally do, seem logically directed towards emulating the human tutor by adding more input channels and modalities. Now, to understand where this particular path is heading, and its inherent limitations, it helps to adopt the perspective of true AI fanatics enthusiasts like Ray Kurzweil. For them, the human brain, though a marvel of evolution, isn't magical. It's an incredibly sophisticated biological computer. And if it's a computer, there's no fundamental metaphysical reason it can't be replicated and eventually surpassed.

Here’s how it goes: the human brain's processing power is often estimated to be in the ballpark of one exaFLOPS – that's a billion billion (1018) floating-point operations per second. It's a staggering number. For a moment though, it might seem AI has already caught up. Elon Musk's xAI, for example, has built a supercomputer cluster called Colossus with 200,000 Nvidia H100 GPUs, aiming for performance that, when optimized for specific AI tasks, can indeed reach into the 200 exaFLOPS range. So, on raw “compute” (a tech industry shorthand for computational resources)2, one might chalk up a point for AI.
But here's the critical distinction: the human brain achieves its exaFLOP performance while consuming a mere 20 watts of power – less than a dim light bulb. That xAI supercomputer? It demands 250 megawatts, millions of times more energy for comparable raw processing output. This colossal energy difference underscores a fundamental challenge. The AAAI's "Future of AI Research" panel report (2025) highlights that: "research on AI algorithms and software systems is becoming increasingly tied to substantial amounts of dedicated AI hardware, notably GPUs" (AAAI, p. 6), and this hardware is notoriously power-hungry.
This brings us back to the core question for AI tutoring: what kind of input, output, and processing is needed to even approximate a good human tutor, and what's the computational cost? Current AI tutors, like Khanmigo, operate primarily on text. They know what a student types. But if a student is silent, the bot is clueless. Are they pondering deeply, grabbing a snack, or have they wandered off entirely? A human tutor, present in the room or even via video, intuits this almost instantly, largely through visual and auditory cues. The subtle shift in posture, the furrowed brow, the ambient noises – these are all data points a human effortlessly processes.
To bridge this gap and truly approximate human intuition, an AI tutor would need to process a far richer stream of data, encompassing:
Seeing the student's work: Real-time screen capture. It exists.
Seeing the student: Webcam feed for facial expressions, gaze (as explored in papers like "Gaze-Based Prediction of Students' Math Difficulties"), and body language. Not creepy at all3…
Hearing the student and their environment: Continuous audio capture for nuanced verbal interaction and contextual sounds.
Communicating naturally: Advanced, low-latency voice synthesis and speech recognition, like chatGPT’s advanced voice mode.
Maintaining context and persona: Perhaps even a dynamic, responsive avatar, like a real zoom tutor that is smiling and softspoken? This also exists.
All these capabilities are here in some form today. But integrating them into a seamless, real-time, interactive experience for millions of students simultaneously represents an astronomical computational load. Each video stream, each audio analysis, each nuanced vocal response consumes significant processing power and, by extension, energy. This isn't just a software challenge; it's a profound hardware and energy challenge. On top of that, the competitive pressure to ship ever more advanced frontier models and capabilities forces AI labs to dedicate substantial amount of their compute budget toward training and fine tuning the next iteration of models. That's the most energy intensive task of all, so they constantly have to arbitrate how to distribute their compute between training and inference4. This explains why OpenAI’s API list has such wild differences in pricing. It also explains why the paid tier of ChatGPT, ChatGPT Plus at about $20/ month was not sustainable to give unlimited access to their most advanced models and they released ChatGPT Pro in December 2024 for $200/month. Do you feel this is expensive? Just wait till you hear about their “PhD-level Agent” idea they’ve been floating around, they apparently plan to charge up to $20,000/month for that one…
There's another critical dimension I haven't touched on here: memory and student knowledge. A human tutor builds a nuanced understanding of each student over time - their background knowledge, misconceptions, interests, and specific challenges. This personalized mental model allows for precise instructional decisions. However, as I explored in detail in my previous article on the personalization paradox, data privacy laws create a fundamental tension between the comprehensive student data AI systems would need to approximate this understanding and the strict limits on what they can legally collect and retain. This creates yet another barrier to truly human-like AI tutoring at scale, entirely separate from the energy and computing constraints discussed above.
The Real Bottleneck: A Triad of Constraints
The dream of a ubiquitous, human-like AI tutor slams headfirst into three interconnected, very physical bottlenecks:

First, compute and chip scarcity. Nvidia, the current king of AI chips, can't make them fast enough. As the AAAI report (p. 41) points out, hardware design is now trying to "accelerate computational operations seen as most relevant given current algorithms in use," and for AI, that means an insatiable demand for specialized GPUs. These aren't just complex to design; their manufacturing, primarily concentrated in Taiwan with TSMC, is a global choke point. Building new fabrication plants, even domestically in the US, is a multi-year, multi-billion dollar endeavor. Elon Musk's ambition to scale xAI's cluster to a million GPUs, a project already consuming the equivalent of 35% of its county's electricity with its current 200,000 GPUs, highlights the scale of demand the industry anticipates.

Second is energy demand. This was a recurring theme in the recent Senate hearing. Here’s what Sam Altman, CEO of OpenAI, stated unequivocally:
“You touched on a great point with energy. I think it's hard to overstate how important energy is to the future here. Eventually, chips, networks, and gear will be made by robots. We'll make that very efficient and cheaper over time, but an electron is an electron. Ultimately, the cost of intelligence—the cost of AI—will converge with the cost of energy. Its abundance will be limited by the abundance of energy. So, in terms of long-term strategic investments for the U.S., I can't think of anything more important than energy. Chips and all the other infrastructure matter too, but I believe energy is where this all ends up.” (Go to 1:31:41 in the video)
He would know what he’s talking about: OpenAI itself is reportedly planning "Stargate," a $100 billion supercomputer project (some estimates go as high as $500 billion) that would require gigawatts of power. The IEA's "Energy and AI" (2025) report paints a stark picture, stating, "A typical AI-focused data centre consumes as much electricity as 100,000 households, but the largest ones under construction today will consume 20 times as much" (IEA, p. 13). Their Base Case projection sees data center electricity consumption more than doubling to around 945 TWh by 2030 (IEA, p. 14), and the AAAI report (p.49) echoes this concern about "Rising Resource Demands of AI Compute." Tom's Hardware correctly notes, "Experts say that data centers will need gigawatts of energy to train future AI models, something that the local power grid will likely be unable to handle without massive upgrades." This isn't a distant concern; it's an immediate operational reality. As Microsoft's Brad Smith mentioned in the Senate hearing, their industry is "only going to account for 15% of the total additional electricity the country is going to need" (01:01:42), implying the overall energy demand growth is massive, and AI is a significant new driver within that.
The proposed solution for projects like Stargate? Often, it's a reliance on Small Modular Reactors (SMRs, or mini nuclear powerplants). Interestingly, Oklo, a startup co-founded by Altman himself, aims to have SMRs operational by 2027. This is an ambitious timeline, especially when established nuclear companies like Holtec International are targeting their "Project 2030" for the US's first functional SMR by then. The optimism surrounding these timelines for SMR deployment to power AI seems, shall we say, substantial. Altman even seems to think nuclear fusion will be operational by 2028. Right.

Third, and perhaps most critically, grid and infrastructure limitations. Even if we could magically produce enough chips - and - SMRs could come online as optimistically projected, our current electrical grid isn't built for this new reality. Check out this exchange (02:32:05) between Senator Lummis of Wyoming and Michael Intrator, CEO of CoreWeave, a recently made public company specializing in providing large-scale, GPU-accelerated computing power for artificial intelligence (AI), machine learning, and high-performance computing workloads:
Sen. Lummis: “Could you elaborate on how current permitting processes have impacted your ability to rapidly deploy AI infrastructure? The more specific you can be, the better.”
M. Intrator: “A quick comment on the patchwork, and then I’ll dive in. The investment we're making on the infrastructure side is enormous, and the idea that such an investment could become trapped in a jurisdiction with specific regulations that prevent full utilization is really very suboptimal. It makes infrastructure decisions incredibly challenging.
As for permitting, whenever this topic comes up, the discussion is excruciating—especially in terms of the ability to build quickly and at scale. And that’s just looking at it from the data center forward, without even getting into the permitting issues related to the energy infrastructure needed to power these large-scale investments, which are essential to advancing artificial intelligence.”
The IEA report (p. 15) estimates that "around 20% of planned data centre projects could be at risk of delays" due to grid connection issues. Building new high-voltage transmission lines, a prerequisite for connecting new large-scale power sources or massive data centers, can take four to eight years in advanced economies, often longer. Intrator’s poignant remark that "We cannot run a 21st century economy on the 20th century's infrastructure" (00:41:04) perfectly encapsulates this challenge. There’s more in these documents if that’s not enough to convince you. I could go on and on. Right after that last punchline, Intrater added that “Since 2018, the computing power necessary for advanced AI models has multiplied approximately 100,000fold.” But the AI explosion is… now?

A Black Swan Caveat
One critical disclaimer I should mention: my entire analysis assumes that Large Language Models remain the fundamental architecture powering AI education tools. Yann LeCun, Chief Scientist at Meta, would disagree with that assumption. He recently declared that he’s “not so interested in LLMs anymore” (00:41). If there's a paradigm-shifting breakthrough—a true black swan event like ChatGPT was in late 2022—all bets are off. I couldn't have predicted ChatGPT's emergence or impact three years ago, and I'm equally blind to whatever revolutionary architecture might be brewing in some lab today. If someone creates an entirely new approach to AI that sidesteps the computational, energy, and infrastructure constraints I've outlined, we could see a dramatically different trajectory. History teaches us humility when making tech predictions, and I'm keenly aware that the most transformative innovations tend to be the ones nobody saw coming. That said, based on the current technological paradigm and its physical limitations, my prediction stands.
CASE IN POINT!
Last minute edit: Literally seconds before I planned to publish this article, I learned about Gemini Diffusion—announced just yesterday during Google I/O 2025. It’s an “extremely low-latency” text generation model of an entirely new kind, claimed to be five times faster than their current fastest model for comparable performance. This piece might already be moot—holy smokes! Watch the presentation and join the waitlist!

My 5-Year Prediction (and What It Means for Educators)
Considering these monumental, interlinked constraints – the silicon supply chain, the sheer energy required for advanced AI, and the creaking electrical grid struggling to deliver that power – my prediction is this:
Truly advanced, multi-modal AI tutors that can genuinely see, hear, and dynamically adapt with the nuance of a human counterpart will not be a widespread, scalable reality in mainstream K-12 education within the next five years (roughly before at least 2030).
What will we see instead?
Smarter Chatbots: Text-based interactions will continue to improve. RAG systems will get better at pulling information from specific curricula. Less hallucinations, no more jailbreaking.
Niche Multi-modal Experiments: For very specific, high-value educational tasks, or within well-funded pilot programs, we might see more sophisticated multi-modal AI tutors. But these will be the exception, not the rule.
Smarter Educational Tools: Expect a merger of traditional Intelligent Tutoring Systems with GenAI - creating more adaptive quizzing, refined content generation for teachers, and better text-based feedback on student work. These will be computationally efficient while claiming to offer "personalization" - though still far from true AI tutoring.
Persistent Hype: The marketing will undoubtedly continue to promise personalized learning nirvana, because that's the nature of the beast. And demo products will do amazing things, but they’ll remain largely out of reach.
For educators, this means a pragmatic approach is essential. The AI super-tutor isn't about to replace human teachers en masse. The focus should remain on leveraging AI as a powerful co-intelligence – for students and teachers – while critically understanding its current capabilities and, more importantly, its very real limitations. The AI revolution in education is happening, but its most ambitious visions are currently tethered by the unglamorous realities of power lines, chip fabs, and energy bills. The future of AI is physical, and that physicality will dictate its pace in our classrooms.
Disclosure: I own stock in Nvidia and CoreWeave, which are mentioned in this article. These holdings did not influence my analysis, but readers should be aware of this potential conflict of interest.
Custom GPTs: Imagine you were so rich you could hire all the help you want. You’d likely have a chef, a nanny, an accountant, a lawyer, etc. All these people have different set of skills, training, and knowledge. Your custom GPTs are kind of like that, it’s your private army of employees that all share a salary of $20/month and who all have specific personalities, knowledge base, and goals, with one thing in common: they mainly produce text. Examples? A “what are we eating for dinner” bot, preloaded with all of your family’s preferences, dietary restrictions, and usual budget. A “report to my boss” bot that has in memory all your previous reports so it knows how to make new ones, and you can focus on content, not language, etc.
When I refer to "compute", I'm talking about the raw processing power needed to run AI systems. This isn't just regular computing power like what's in your laptop - it's specialized hardware, primarily GPUs (Graphics Processing Units) and custom AI chips, designed specifically to handle the massive parallel calculations required for training and running advanced AI models. Think of compute as the engine room of AI - without enough of it, the most sophisticated algorithms remain theoretical rather than practical. And unlike software, which can be copied infinitely at virtually no cost, compute is a physical resource bound by manufacturing constraints, supply chains, and energy requirements.
Gaze-Based Prediction is not new, I’ve seen papers from 2010 on the topic, it’s probably ripe for integration. Here’s a recent paper:
“In our study, the eye tracking data of 143 students reveal how students’ math tasks in context of graphically differentiation can be predicted (…) The prediction results improve with increasing processing time and achieve already good values long before the solution process of the tasks is completed. Our results show that certain student difficulties can be detected very early during the task solution process. Although this approach has been demonstrated for a sub-area of calculus, it is transferable to other fields of the STEM domain and therefore has much wider scope.” (Abstract)
"Inference" refers to when an AI model is actually doing its job - answering questions, generating text, analyzing images, etc. for YOU. It’s what happens between you pressing ‘enter’ after typing a prompt and the bot delivering the output. If you’ve used the thinking models, they’re basically the same then the regular ones, but with more compute allocated for inference, hence the long wait.
Great post. Super interesting. I get overwhelmed with the tech side of the AI discussion but, as you point out, all bets are off if new breakthroughs take place which I think the AI people are banking on. That's certainly Daniel Kokotajlo's view with AI 2027. As a lowly teacher who is at the mercy of all this, I can only see what's in front of me, but it's still substantial. I'm frankly not worried about teacher robots anytime soon, but with AI embedded in everything, we have to find a way to reengineer learning experiences for students that are mindful of what they are exposed to. Thanks for the post! I learned a lot!